Here is a simple scheduling problem [1]:
- We have \(T\) time periods (weeks)
- and \(N\) jobs to be scheduled.
- Each job has a duration or processing time (again expressed in weeks), and a given resource (personnel) requirement during the execution of the job. This demand is expressed as: \(\color{darkblue}{\mathit{resource}}_{j,t}\) where \(j\) indicates the job and \(t\) indicates the week since the start of the job.
- Not in [1], but I added them to make things a bit more realistic: we have some release dates indicating that a job may not start before a given date. A reason can be that raw material is not available before that date.
- Similarly, I added due dates: a job must finish before a given date.
- The objective is to minimize the maximum amount of resources we need over the whole planning period. We can think of this as the capacity we need (e.g. number of personnel).
Data
---- 32 SET jjobs
job1 , job2 , job3 , job4 , job5 , job6 , job7 , job8 , job9 , job10, job11, job12
job13, job14, job15, job16, job17, job18, job19, job20, job21, job22, job23, job24
job25, job26, job27, job28, job29, job30, job31, job32, job33, job34, job35, job36
job37, job38, job39, job40, job41, job42, job43, job44, job45, job46, job47, job48
job49, job50, job51, job52, job53, job54, job55, job56, job57, job58, job59, job60
---- 32 SET tweeks
week1 , week2 , week3 , week4 , week5 , week6 , week7 , week8 , week9 , week10, week11
week12, week13, week14, week15, week16, week17, week18, week19, week20, week21, week22
week23, week24, week25, week26, week27, week28, week29, week30, week31, week32, week33
week34, week35, week36, week37, week38, week39, week40, week41, week42, week43, week44
week45, week46, week47, week48, week49, week50, week51, week52
---- 32 PARAMETER data job data and resource usage
release due proctime week1 week2 week3 week4 week5
job1 611
job2 30555323
job3 223143
job4 2244
job5 241
job6 13254
job7 12255
job8 544444
job9 11
job10 113314
job11 29512554
job12 223412
job13 555523
job14 1741232
job15 2311
job16 745313
job17 912
job18 251
job19 61843234
job20 193421
job21 22252
job22 17253
job23 11
job24 12
job25 3331
job26 21545132
job27 251
job28 44555
job29 1245235
job30 2333241
job31 182413
job32 13341
job33 12
job34 14523214
job35 233
job36 244
job37 3154
job38 2241441
job39 294742443
job40 3111
job41 123555
job42 15
job43 211
job44 13
job45 9215
job46 1315
job47 124042132
job48 3133
job49 443522
job50 234
job51 42152
job52 245241215
job53 42323
job54 20243
job55 11
job56 11
job57 42321
job58 153442
job59 14
job60 2041445
- The release date can be empty. That means we can start processing immediately on the corresponding job. Otherwise, we define the release date as the first week we can execute the job. In other words, the release date uses the beginning of the period. An empty release date can be interpreted as a release date of week 1.
- The due date is also referring to the beginning of the period. If the due date is 4, we can still work on the job in week 3. An empty due date is the same as a due date of week 53.
- The numbers under the week columns indicate the resource usage in that week (measured since the start of the job). Obviously, the length of the resource usage data is equal to the processing time or duration of the job.
Basic model
| MIP Model 1 |
|---|
| \[\begin{align}\min\>&\color{darkblue}{\mathit{maxres}} \\ & \sum_t \color{darkred}x_{j,t}=1 && \forall j \\ & \color{darkblue}{\mathit{maxres}}\ge \sum_j \sum_{t=t'-\color{darkblue}{\mathit{proctime}}_j+1}^{t'} \color{darkblue}{\mathit{resource}}_{j,t'-t+1}\cdot \color{darkred}x_{j,t} && \forall t' \\ & \sum_t t\cdot \color{darkred}x_{j,t}\ge\color{darkblue}{\mathit{release}}_{j} && \forall j\\ & \sum_t (t+\color{darkblue}{\mathit{proctime}}_j-1)\cdot \color{darkred}x_{j,t}\le\color{darkblue}{\mathit{due}}_{j}-1 && \forall j \\ & \color{darkred}x_{j,t} \in \{0,1\}\end{align}\] |
My model
---- 88 PARAMETER resmap resource mapper
week1 week2 week3 week4 week5 week6 week7 week8 week9
job1 .week6 1
job1 .week7 1
job1 .week8 1
job1 .week9 1
job2 .week1 55323
job2 .week2 55323
job2 .week3 55323
job2 .week4 55323
job2 .week5 55323
job2 .week6 5532
job2 .week7 553
job2 .week8 55
job2 .week9 5
job3 .week1 143
job3 .week2 143
job3 .week3 143
job3 .week4 143
job3 .week5 143
job3 .week6 143
job3 .week7 143
job3 .week8 14
job3 .week9 1
job4 .week2 44
job4 .week3 44
job4 .week4 44
job4 .week5 44
job4 .week6 44
job4 .week7 44
job4 .week8 44
job4 .week9 4
. . .
The second data structure I created is a set \(\color{darkblue}{\mathit{ok}}_{j,t}\) indicating which time slots are allowed for job \(j\) to start. This can look like this (again a partial view):
---- 93 SET okallowed slots for jobs to start
week1 week2 week3 week4 week5 week6 week7 week8 week9
job1 YES YES YES YES
job2 YES YES YES YES YES YES YES YES YES
job3 YES YES YES YES YES YES YES YES YES
job4 YES YES YES YES YES YES YES YES
job5 YES YES YES YES YES YES YES YES YES
job6 YES YES YES YES YES YES YES YES YES
job7 YES YES YES YES YES YES YES YES YES
job8 YES YES YES YES YES YES YES YES YES
job9 YES YES YES YES YES YES YES YES YES
job10 YES YES YES YES YES YES YES YES
job12 YES YES YES YES YES YES YES YES YES
job13 YES YES YES YES YES YES YES YES YES
job14 YES YES YES YES YES YES YES YES YES
job16 YES YES YES
job17 YES
job18 YES YES YES YES YES YES YES YES YES
job19 YES YES YES YES
job20 YES YES YES YES YES YES YES YES YES
. . .
After calculating these two symbols, I wrote the model as:
| MIP Model 2 |
|---|
| \[\begin{align}\min\>&\color{darkblue}{\mathit{maxres}} \\ & \sum_{t|\color{darkblue}{\mathit{ok}}(j,t)} \color{darkred}x_{j,t}=1 && \forall j \\ & \color{darkred}{\mathit{use}}_{t'} = \sum_{j,t} \color{darkblue}{\mathit{resmap}}_{j,t,t'} \cdot \color{darkred}x_{j,t} && \forall t'\\ & \color{darkblue}{\mathit{maxres}}\ge \color{darkred}{\mathit{use}}_{t} && \forall t \\ & \color{darkred}x_{j,t} \in \{0,1\}\end{align}\] |
- The constraints for the release and the due date have disappeared. These are now taken care of by the set \(\color{darkblue}{\mathit{ok}}_{j,t}\) and the parameter \( \color{darkblue}{\mathit{resmap}}_{j,t,t'}\). We just never consider an \(\color{darkred}x_{j,t}\) that is outside the allowed window.
- That means our generated model is much smaller: fewer variables and fewer constraints.
- I added a variable \(\color{darkred}{\mathit{use}}_{t}\) indicating how many resources we need at each time period. This is not really needed but useful in reporting. Instead of recomputing this quantity during reporting, I added it to the model. Sometimes we add so-called "accounting rows" to models to compute quantities used for reporting. They are meant to make the solution easier to interpret.
- Notice that our equations are much simpler and that much of the debugging has happened before we even wrote the first equation.
Results
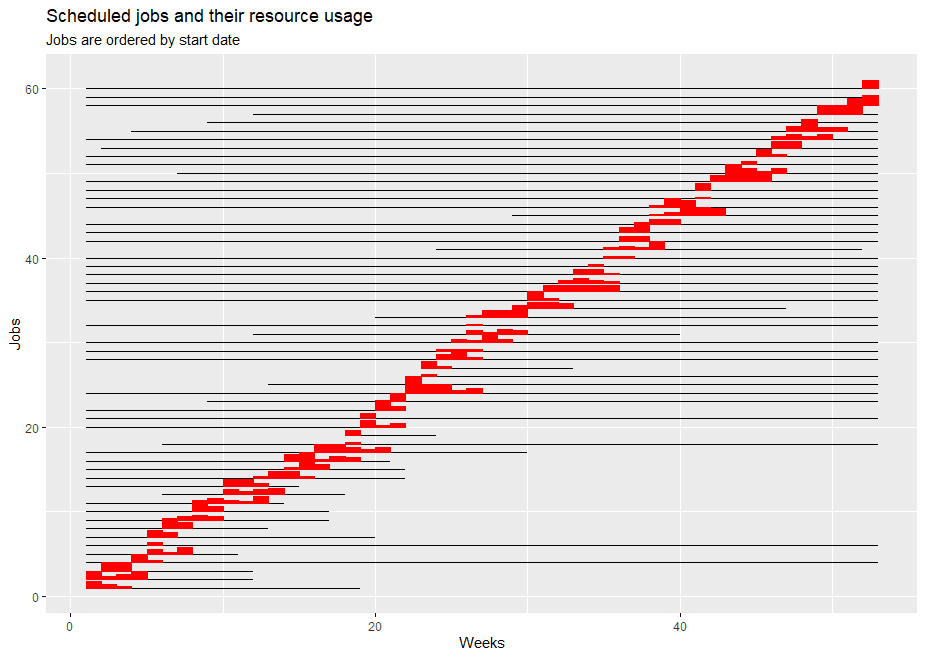
---- 140 VARIABLE x.L start of job
week1 week2 week4 week5 week6 week8 week10 week12 week14
job3 1
job6 1
job7 1
job10 1
job14 1
job18 1
job19 1
job20 1
job22 1
job26 1
job29 1
job33 1
job34 1
job38 1
job54 1
job58 1
+ week16 week18 week19 week20 week22 week23 week24 week25 week26
job1 1
job2 1
job12 1
job13 1
job15 1
job21 1
job30 1
job31 1
job32 1
job40 1
job44 1
job45 1
job46 1
job47 1
job51 1
job56 1
job60 1
+ week29 week30 week31 week32 week33 week34 week35 week36 week37
job8 1
job23 1
job25 1
job27 1
job35 1
job39 1
job43 1
job48 1
job50 1
job52 1
job57 1
+ week38 week41 week42 week43 week44 week45 week46 week47 week48
job4 1
job5 1
job11 1
job16 1
job17 1
job24 1
job28 1
job37 1
job49 1
job53 1
job55 1
job59 1
+ week49 week51 week52
job9 1
job36 1
job41 1
job42 1
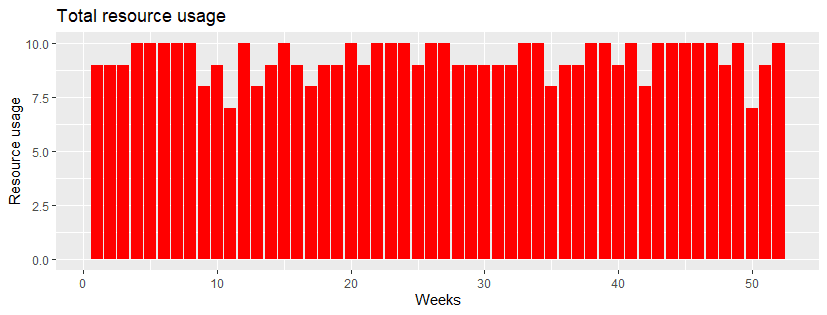
---- 140 VARIABLE use.L resource usage
week1 9, week2 9, week3 9, week4 10, week5 10, week6 10, week7 10, week8 10
week9 8, week10 9, week11 7, week12 10, week13 8, week14 9, week15 10, week16 9
week17 8, week18 9, week19 9, week20 10, week21 9, week22 10, week23 10, week24 10
week25 9, week26 10, week27 10, week28 9, week29 9, week30 9, week31 9, week32 9
week33 10, week34 10, week35 8, week36 9, week37 9, week38 10, week39 10, week40 9
week41 10, week42 8, week43 10, week44 10, week45 10, week46 10, week47 10, week48 9
week49 10, week50 7, week51 9, week52 10
---- 140 VARIABLE maxres.L = 10maximum resource usage
---- 148 PARAMETER results compare statistics
model 1 model 2
vars 3121.0002178.000
discr 3120.0002125.000
equs 232.000164.000
status Optimal Optimal
obj 10.00010.000
time 3.8754.312
iterations 617.000617.000
Obviously, the first model is bigger, but the presolver takes care of that. Note that this particular data set is extremely easy to solve (these models did not require any nodes). But just slightly different data may make this model much more difficult to solve to optimality.
Conclusion
References
- Scheduling minimization Integer Programming problem formulation, https://or.stackexchange.com/questions/6606/scheduling-minimization-integer-programming-problem-formulation
Appendix: GAMS model
$ontext |