- A matrix with with entries \(\color{darkblue}A^0_{i,j}\ge 0\).
- Row- and column-totals \(\color{darkblue}r_i\) and \(\color{darkblue}c_j\).
| Matrix Balancing Problem |
|---|
| \[\begin{align}\min\>&{\bf{dist}}(\color{darkred}A,\color{darkblue}A^0)\\ & \sum_i \color{darkred}A_{i,j} = \color{darkblue}c_j && \forall j\\ & \sum_j \color{darkred}A_{i,j} = \color{darkblue}r_i && \forall i \\&\color{darkred}A_{i,j}=0 &&\forall i,j|\color{darkblue}A^0_{i,j}=0\\ &\color{darkred}A_{i,j}\ge 0 \end{align} \] |
 |
| Approximate the matrix subject to row- and column-sum constraints |
Data
- Generate the sparsity pattern of the matrix
- Populate the non-zero elements of the matrix.
- Calculate the row and column sums.
- Perturb the row and column sums. I used a multiplication with a random number. This makes sure things stay positive.
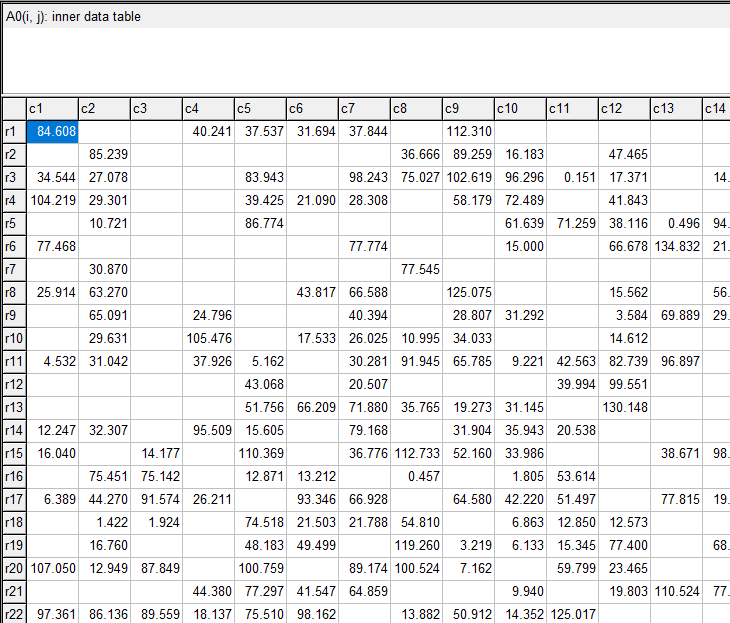 |
Partial view of the generated matrix \(\color{darkblue}A^0\). |
This is not a small problem, with about half a million (non-linear) variables. But this is still way smaller than the problems we may see in practice, especially when we regionalize.
The RAS algorithm
| RAS Algorithm |
|---|
| loop # row scaling \(\rho_i := \displaystyle\frac{r_i}{\sum_j A_{i,j}}\) \(A_{i,j} := \rho_i\cdot A_{i,j}\) # column scaling \(\sigma_j := \displaystyle\frac{c_j}{\sum_i A_{i,j}}\) \(A_{i,j} := \sigma_j\cdot A_{i,j}\) until stopping criterion met |
---- 94 PARAMETER trace RAS convergence
||rho-1|| ||sigm-1|| ||both||
iter1 0.044998550.055590310.05559031
iter2 0.002330510.000123700.00233051
iter3 0.000009580.000000590.00000958
iter4 0.000000043.587900E-90.00000004
---- 95 RAS converged.
PARAMETER niter = 4.000 iteration number
Entropy Maximization
| Cross-Entropy Optimization Problem |
|---|
| \[\begin{align}\min&\sum_{i,j|A^0_{i,j}\gt 0}\color{darkred}A_{i,j} \cdot \ln \frac{\color{darkred}A_{i,j}}{\color{darkblue}A^0_{i,j}}\\ & \sum_i \color{darkred}A_{i,j} = \color{darkblue}c_j && \forall j\\ & \sum_j \color{darkred}A_{i,j} = \color{darkblue}r_i && \forall i \\&\color{darkred}A_{i,j}=0 &&\forall i,j|\color{darkblue}A^0_{i,j}=0\\ &\color{darkred}A_{i,j}\ge 0 \end{align} \] |
---- 222 PARAMETER report timings of different solvers
obj iter time
RAS alg -7720.0834.0000.909
CONOPT -7720.083124.000618.656
IPOPT -7720.08315.000171.602
IPOPTH -7720.08315.00025.644
KNITRO -7720.08310.00065.062
MOSEK -7720.05113.00011.125
Notes:
- The objective in RAS was just an evaluation of the objective function after RAS was finished.
- In the GAMS model we skip all zero entries. We exploit sparsity.
- CONOPT is an active set algorithm and is not really very well suited for this kind of models with many super-basic variables. (Super-basic variables are non-linear variables between their bounds).
- IPOPTH is the same as IPOPT but with a different linear algebra library (Harwell's MA28 instead of MUMPS). That has quite some impact on solution times.
- MOSEK is the fastest solver, but I needed to add an option: MSK_DPAR_INTPNT_CO_TOL_REL_GAP = 1.0e-5. This may need a bit more fine-tuning. Without this option MOSEK would terminate with a message about lack of progress. I assume it gets a little bit in numerical problems.
- MOSEK is not a general-purpose NLP solver. We had to use an exponential cone equation. That is a bit more work, and the resulting model is not as natural as the other ones.
- The difference between the CONOPT solution and RAS solution for \(\color{darkred}A\) is small:
---- 148 PARAMETER adiff = 1.253979E-7 max difference between solutions
 |
| Entropy Models [2] |
References
- Iterative Proportional Fitting, https://en.wikipedia.org/wiki/Iterative_proportional_fitting
- Amos Golan. George Judge and Douglas Miller, Maximum Entropy Econometrics, Robust Estimation with Limited Data, Wiley, 1996
- McDougall, Robert A., "Entropy Theory and RAS are Friends" (1999). GTAP Working Papers. Paper 6.
Appendix: GAMS Model
$ontext |