There are a few database systems that are a bit different. They are libraries that can be linked directly to your application. Linking can be done statically (during the compilation/linking step) or dynamically (using a shared library or DLL). Here I want to show two cases:
- SQLite used from R on data frames
- DuckDB used from Python, again on data frames
So these databases don't only run inside R or Python but also can operate directly on data frames.
R and sqldf
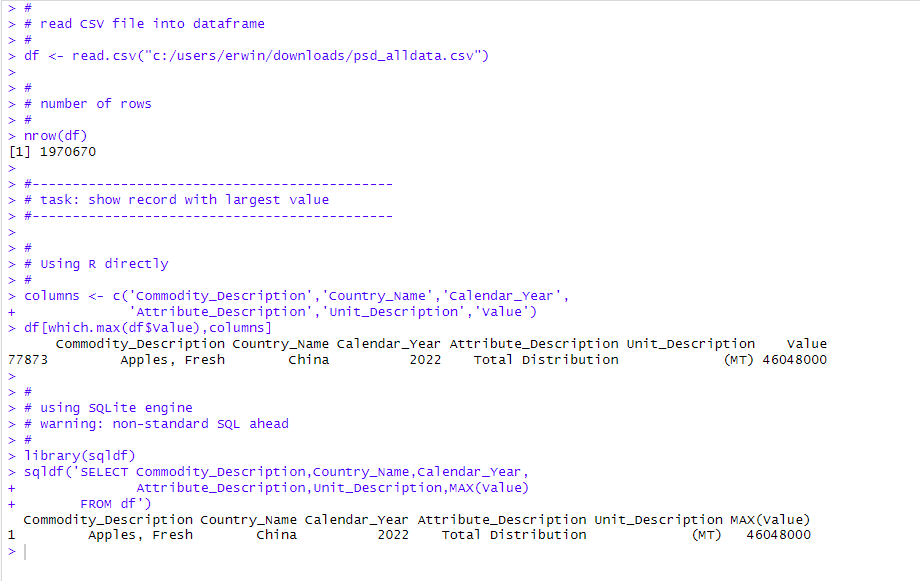
I am loading a large CSV file here, and I want to find a record with the largest value. I do this in two different ways:
- With standard R, using the which.max function,
- Using sqldf and an SQL query.
The SQL query is a bit non-standard. Most databases will require a GROUP BY clause in a query with an aggregate function. SQLite does not and will return values for which the maximum is assumed. A more standard approach would be to use a subquery:
SELECT *FROM dfWHERE Value = (SELECT MAX(Value) FROM df)
Python and DuckDB
DuckDB [1] is a relatively new column-oriented database. Just like SQLite, it can be used as an in-process, in-memory database.

Again, first, I use a "native" method, followed by an SQL approach.
Running SQL queries against data frames is an alternative way to select data. In some cases, that can be more intuitive, especially if you are familiar with SQL.
References
- DuckDB is an in-process SQL OLAP database management system, https://duckdb.org/